
Introduction
Transfer Learning is a technique used to improve the data efficiency of neural networks. Suppose we want to train a neural network to solve the task of classifying a image as that of a cat or dog, but have very little data. Instead of training a neural network from scratch, we retrieve a neural network trained to solve a different task (with a huge amount of data), and further train its parameters (fine-tune) to solve our downstream task of classifying an image as that of a cat or dog. This usually leads to better performance, and faster convergence.
A recent paper titled Transfusion: Understanding Transfer Learning for Medical Imaging - published by Google Brain - found that a small convolutional neural network trained from scratch performs competitively with large neural network that was fine-tuned on the task after being trained on the ImageNet task. This is counter-intuitive because larger neural networks typically outperform small networks on complex tasks, if sufficient data is available. Since Transfer Learning typically improves data efficiency, one would expect large models pre-trained on a huge amount of data to outperform a small model trained from scatch. I investigated why this is the case by conducting several experiments on the CheXpert Edema detection task.
Conjectures
I formed the following conjectures that might explain the results of the paper:
- Deep models are too difficult to train: In the past, deeper models would underfit compared to shallow models. This was counter-intuitive because a 50-layer neural network is at least as complex as a 5-layer neural network. i.e. the set of all models that can be represented by 50-layer neural network is a super set of all the models that can be represented by a 5-layer neural network, as 45 layers could learn the identity function. This was a result of deeper neural networks being more difficult to train than shallow network, and unrelated to model complexity.
- The task is too simple: Medical images are highly curated compared to your typical dataset of photographs: They are taken by a professional using machines of medical-grade precision, with the patient in a specific pose. In comparison, ImagesNet images - which were taken from the internet - were captured by an amateur using their cell-phone camera. After exploring a subset of the Chest X-rays, I found that they were much more homogeneous than ImageNet images: The frontal images appeared to be affine transformations of each other, with a little variation in brightness, and a bit of text in the corner. So perhaps we don’t require a complex model to solve the task.
- More data is not needed: CheXpert already contains 200,000 images. This is not as large as ImageNet - which contains 14,000,000 images - but perhaps it sufficiently represents the distribution of chest x-rays. As mentioned earlier, the CheXpert images are highly curated and more homogeneous.
- Domains are too different: Perhaps the domain of chest x-ray classification (CheXpert) and photograph classification (ImageNet) are too different, so a model trained on ImageNet does not transfer well to CheXpert.
Experiments
I considered the following architectures:
- Resnet-50
- Resnet-34
- Resnet-18
- CBR-Large-Wide
- CBR-Large-Tall
- CBR-Small
- CBR-Tiny
The details of the four CBR (convolution-batchnorn-relu) architectures can be found in the Transfusion paper. They are basically 5 to 6 stacks of convolution, batchnorm, relu and max pooling, followed by a global average pooling layer and fully connected layer.
All models were trained on the CheXpert training split, and evaluated on the CheXpert validation split in terms of Area Under ROC. Unless stated otherwise, they were trained and tested on the task of Edema detection.
Details:
- Number of epochs: 100
- Optimizer: Adam
- Initial learning rate: Calculated using the Learning Rate Range Test.
- Scheduler: Anneal by a factor of 10 when training loss does not increase for 10 epochs.
- Augmentation: Random Affine
Training Difficulty and Task Complexity
Larger models usually lead to better performance on the training dataset. I plotted the training curves of the 3 resnet models and the 2 large CBR models. If the task is too simple, then the simple models should have the same training loss and as the complex models. If the deeper models are too difficult to train, then the shallow models should have better training loss than the deeper models.
Dataset Bottle-neck
Larger datasets usually lead to better performance on the test dataset. To investigate whether the task is already sufficiently data efficient, I plotted the performance of the CBR-Large-Wide model as a function dataset size. If it is, then performance should improve on increasing the dataset. I also plotted performance as a function of model size and depth while using the entire dataset, and only 5,000 datapoints.
Domain Difference
To investigate whether the lack of performance improvement is due to the difference in domains of upstream task and downstream task, I pre-trained a CBR-Large-Wide model on the CheXpert Consolidation detection task and fine-tuned it on the Edema detection task. I plotted performance as a function a function of dataset size. I also considered freezing the backbone of the model, as it usually leads to improved performance while using very little data.
Results
Training Curves
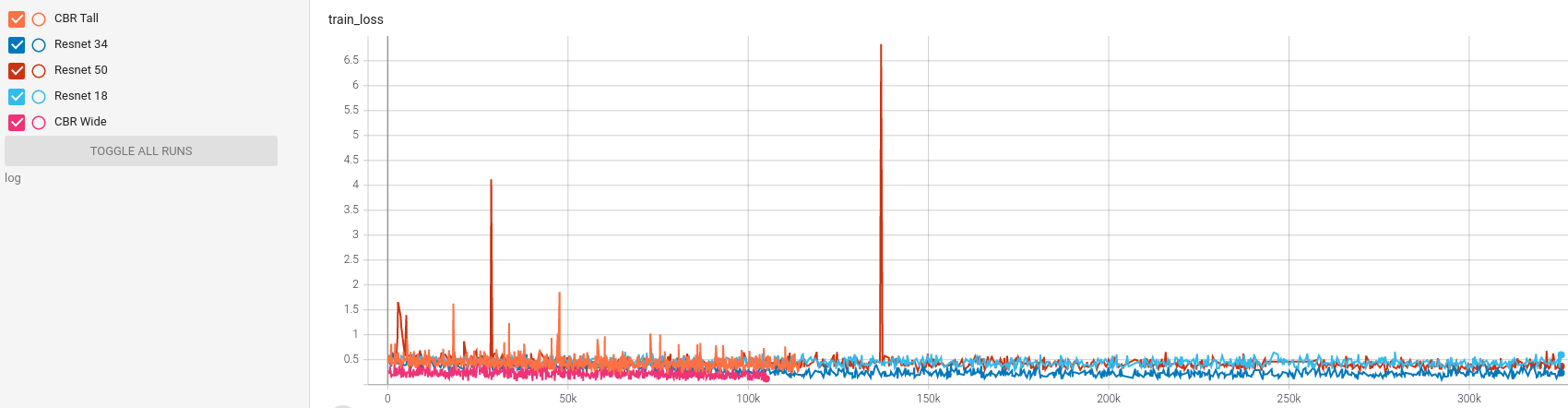
Figure 1 suggests that training is difficult for Resnet-50. This could be a result of the dataset being highly class-imbalanced. Future work will explore the effect of class balancing techniques such as over-sampling.
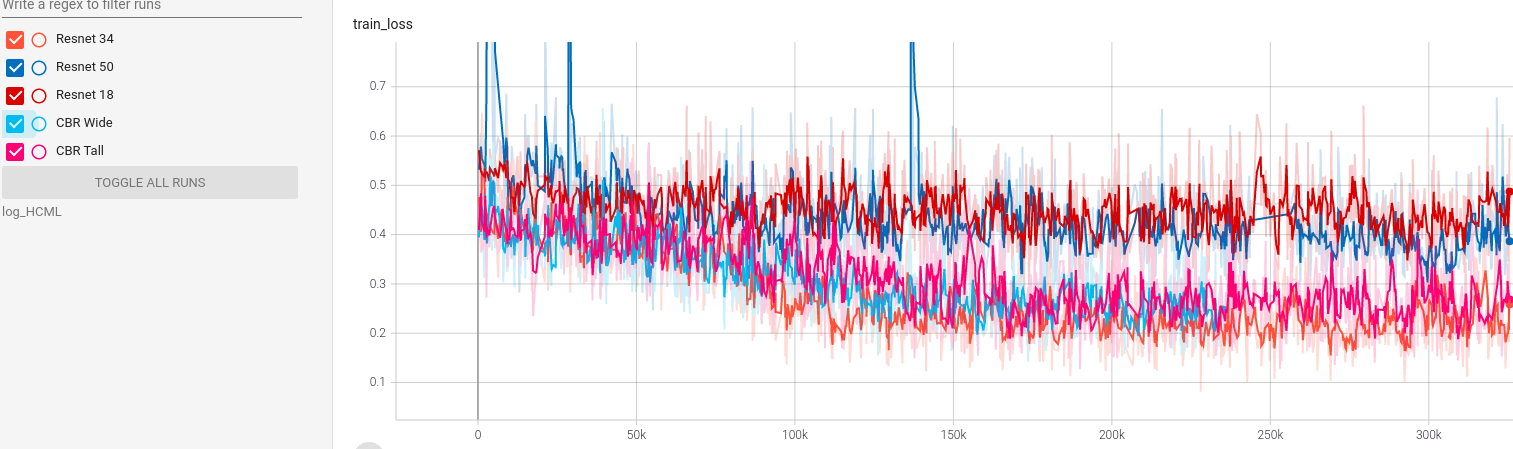
From figure 2, the ranking in terms of training loss appears to be:
CBR-Large-Wide = Resnet-34 = CBR-Large-Tall > Resnet-18 = Resnet-50
Resnet-34 outperforms Resnet-18 and Resnet-50, which suggests that the relative underfitting is not solely due to model depth.
Performance versus data
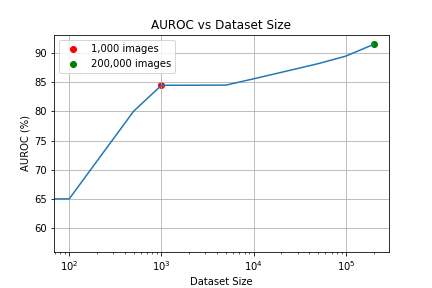
According to figure 3, increasing the dataset size leads to better performance, but not by much. Increasing the dataset size from 50K to 200K increased AUROC by 3.3%. In comparison using a ImageNet pre-trained CBR-Large-Wide increased AUROC by 2%. For more context, it was illustrated in the CPC paper that the performance of Resnet-50 on ImageNet increases by 15% on increasing the dataset size from 120K to 240K.
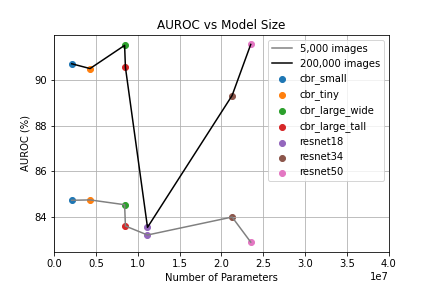
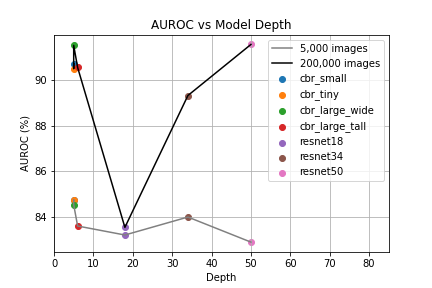
According to figure 4, model complexity mostly seems to have little effect on data scalibility. Resnet-18 scales significantly worse than the simpler models and Resnet-34 scales a little worse.
The ranking in terms of performance on validation set appears to be:
Resnet-50 = CBR-Large-Wide > CBR-Large-Tall = CBR-Small = CBR-Tiny > Resnet-34 > Resnet-18
Strangely, Resnet-50 performs the worst on the training set, and the best on the validation set. This is counter-intuitive because performance on the training set is usually better than that on the validation set, as the parameters of the model are optimized for the training set. This suggests that the distribution of the validation set is not similar to the distribution of the training set.
Transfer Learning from Chest X-rays
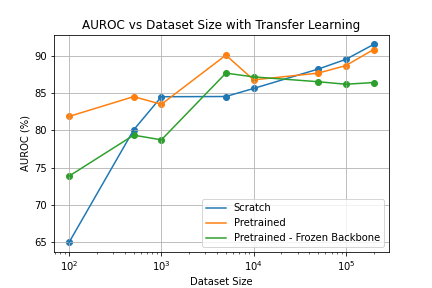
According to figure 5, the models pre-trained on CheXpert Consolidation detection perform competitively with the models trained from scratch on 50,000 and 100,000 data points. This further suggests that dataset size is not longer a bottle-neck in the 50,000 - 200,000 range. However, pre-training did improve performance on 5,000 data-points, implying that the results of the Google Brain paper were partially due to domain difference. However, it should be investigate whether pretraining on the same domain but not the same images have a similar benefit.
Shockingly, validation performance of the fine-tuned model sometimes drops on a larger dataset. This is not the case when training from scratch. One might suspect that the data subset used for fine-tuning was luckier than the one used for training from scratch. But this is not possible as the random split was seeded.
Surprisingly, the frozen-backbone fine-tuned model performs worse than the fine-tuned model on 100 x-rays (very little data), which suggests that the backbone does not generalize well.
Conclusion
The experiments I conducted suggested that:
- The difficulty in training complex models is a performance bottle-neck, but depth is not the only factor contributing to the difficulty. The highly class-unbalanced nature of medical image datasets could be a factor contributing to this.
- Dataset size is not a significant performance bottle-neck in the 50,000 - 200,000 data regime, compared to ImageNet.
- Model complexity has little effect on data scalability, and Resnet-18 scales significantly worse than simpler models. Further investigation is required to understand why this might be the case.
- Pre-trained models may perform worse with more data, but models trained from scratch do not. This is very counter-intuitive and further investigation is required to understand why this might be the case.
- Pre-training on a more similar domain does improve performance in the small-data regime, which was not the case while pre-training on ImageNet and transfering to CheXpert.
Please note that experiments were not as extensive due to computational constraints, and more should be conducted to improve the confidence of these findings.
Implementation
Github repository: https://github.com/SohamTamba/HealthcareMachineLearning