
Introduction
Training an neural network agent to solve a task in an environment end-to-end is usually very data inefficient. One usually requires samples of the order of $10^5$ to solve even a simple task, such as Bipedal Walker. A possible solution to this issue is to leverage unsupervised pre-training to train the model backbone prior to training the model. Recent methods have found success in applying these techniques to solve simple tasks with less data, so we hoped to do the same for a complex task, which is the CARLA Challenge. Current solution to the CARLA Challenge - among the ones published - rely on privelleged information provided by the simulator to train an agent, such as the location of all traffic lights. We attempt to solve the task without this information.
Unfortunately, we under-estimated the difficulty of this task and could not conduct much experimentation within the deadline.
CARLA Challenge
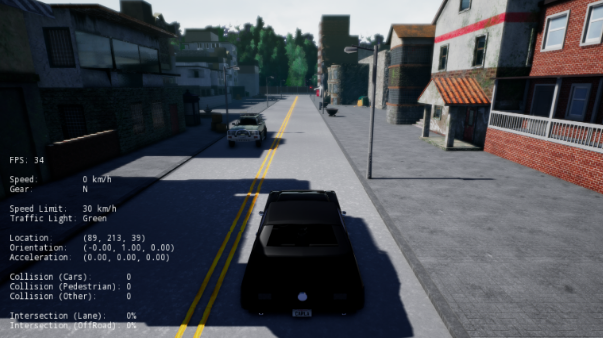
The agent is tasked with navigating from a starting way-point to destination way-point, with minimum collisions and traffic violations. The agent must also follow a list of intermediate way-points and high level instructions. The agent’s actions consist of acceleration, throttle and brake. Example:
Start Way-point = (10.32, 56.12)
High-level instruction = Move Forward
Intermediate Way-point = (12.32, 56.12)
High-level instruction = Turn Left
Intermediate Way-point = (12.32, 56.15)
High-level instruction = Move Forward
Destination Way-point = (12.32, 58.15)
The agent has access to the following sensors:
- 4 cameras
- 1 lidar
- 2 radars
- GNSS, which provides the location of the car
- IMU, which provides information regarding the car’s inertia
- Speedometer
Related Work
[1] used only unsupervised pre-training techniques to train a model backbone, and trained a model on top of it to solve several simple reinforcement learning tasks. They explicitly trained a backbone to produce image representations that are similar for images belonging to temporally adjacent frames, invariant to augmentations, and used a contrastive loss to avoid mode collapse. [2] attempts to solve the CARLA Challenge by training a teacher model whose input is the segmented bird’s eye view of the car’s surroundings, and then training a student model whose input is the photographs taken by the ego car’s camera. They employ immitaion learning techniques. [3] attempts to solve the task by using traffic light information and segmentation masks of the photographs taken by ego car’s camera to train a model backbone. They employ Deep Q Learning techniques.
Method
Our project consists of three phases:
- Data Collection
- Unsupervised Pre-training
- Downstream Task Training
Data Collection
We used CARLA’s auto-pilot to drive the car in multiple scenes, and save its camera, GNSS, IMU, speed-o-meter output, the upcoming way-point, the high-level instruction, and the actions of the auto-pilot. We programmed the simulator to change the weather every 100 time steps, so that a model trained on this data would be invariant to the weather

In total, we collected 30,000 data points.
Unsupervised Pre-training
Swapping Assignments between Views (SwAV) [4] is a unsupervised pre-training technique that achieved state-of-the-art results on Computer Vision tasks, while requires much less GPU memory than its predecessors. We used this technique to conudct the unsupervised pretraining, but made a minor modification of using augmentations of temporally adjacent images to obtain multiple views of a data point, instead of augmentations of the same image. We also used less color jitter and no horizontal flip, because we do not want our encoder to be invariant to those transformations. If it is invariant to color jitter, then it would be unable to recognize the color of a traffic light. If it were invariant to horizontal flip, then it would be unable to differentiate a left turn from a right turn.
We initially trained a Resnet-50 backbone, but found that it was too large to run simultaneously with CARLA; So we trained a Resnet-18 backbone. In hindsight, we should have started with a Resnet-18. Training a Resnet-50 took 8 days (including time for HPC to allocate 4x P40 GPUs).
CARLA Training
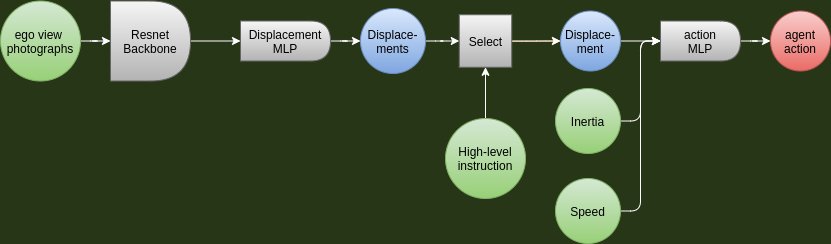
We trained a MLP on top of the backbone mentioned above to predict where the auto-pilot would move the car to for each of the 8 possible high-level commands. We trained another simple MLP to output the 3 actions of the agent, with target displacement, current inertia and speed as its input. This is similar to the algorithm used by [2].
Results
Unsupervised Pre-training
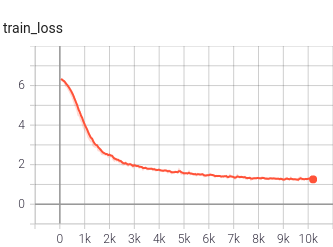
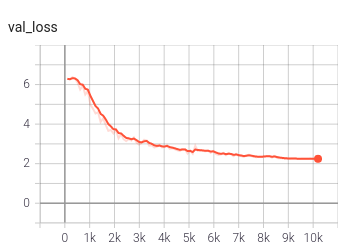
The training curves for temporal SwAV look good.
CARLA
We found that our agent does not perform nearly as well as the ones submitted to the CARLA Leaderboard. It achieves a score of 1% to 2%, as opposed to [2] and [3], which achieve a score of 10.86% and 6.50%. We found that it has trouble correcting its actions. This is likely an issue of insufficient data collection, augmentation and hyper-parameter tuning.
Video 1 demonstrates the agent driving on a straight road.
Video 2 demonstrates the agent attempting to take a right turn. It does not turn sharply enough, and hits the side-walk.
Conclusion
We attempted to train an agent to solve the CARLA challenge, while decoupling representation learning from solving the downstream task. We could not achieve a performance competitive with the state-of-the-art solutions.
Bibliography
- A. Stooke, K. Lee, P. Abbeel, and M. Laskin. Decoupling representation learning from reinforcement learning. arXiv:2004.14990.
- D. Chen, B. Zhou, V. Koltun, and P. Krahenbuhl. Learning by cheating. CoRL, 2019.
- M. Toromanoff, E. Wirbel, and F. Moutarde. End-to-end model-free reinforcement learning for urban driving using implicit affordances. CoRR, 2019.
- Mathilde Caron, Ishan Misra, Julien Mairal, Priya Goyal, Piotr Bojanowski, and Armand Joulin. Unsupervised learning of visual features by contrasting cluster assignments. NeurIPS, 2020